Table of Contents
Genehmigt
In den letzten Tagen haben uns einige unserer Käufer gemeldet, dass sie auf einen Zusammenhang zwischen dem perfekten Typ-1-Fehler und der Auswirkung des Angebots gestoßen sind.
Die Wahrscheinlichkeit, die von allen Fehlern 1. Art ausgeht, ist oft relativ zu Alpha bekannt, während ein Teil der Wahrscheinlichkeit praktisch aller Fehler 2. Art normalerweise als Beta angesehen wird. Stärke ist die sichere Möglichkeit, Nullspekulationen zurückzuweisen, wenn sie eigentlich falsch sein sollten.
CO-6. Wenden Sie die klassischen Konzepte von Wahrscheinlichkeit, Zufallsvariation, kombiniert mit häufig verwendeten statistischen Risikoverteilungen an.
LO 6.28: Definiere Typ-I- und Typ-II-Fehler in normal für sehr spezifische Szenarien.
LO 6.29: Erklären Sie das Konzept, das sich aus allen statistischen Testdrucken ergibt, einschließlich unserer wirklichen Beziehung zwischen Leistung, Stichprobengröße und dann Effektgröße.
Fehler vom Typ I und Typ II beim Testen von Hypothesen
Wir stimmen nicht zu, dass wir nicht garantieren, welche Experten sagen, dass wir mit diesem Hypothesentest die richtige Entscheidung treffen werden. Sie werden allmählich erkennen, dass es in dieser Hinsicht immer ein gewisses Maß an Unsicherheit in Statistiken geben muss.
Lassen Sie uns über die Sprache nachdenken, die wir bereits kennen, und die Schwierigkeiten identifizieren, denen wir bei Bewertungshypothesen begegnen könnten. Wenn wir eine Theorie testen, wählen wir basierend auf unseren Daten eine von zwei gehandhabten Ausgaben aus.
Relevant fasst die vier möglichen Ergebnisse zusammen, die sich aus einem Annahmetest ergeben können. Beachten Sie, dass die Zeilen die Art der Entscheidung bezüglich der Hypothese treffen, während die Spalten in der Realität um die vollständige Wahrheit (normalerweise unbekannt) kämpfen.
Genehmigt
Das ASR Pro-Reparaturtool ist die Lösung für einen Windows-PC, der langsam läuft, Registrierungsprobleme hat oder mit Malware infiziert ist. Dieses leistungsstarke und benutzerfreundliche Tool kann Ihren PC schnell diagnostizieren und reparieren, die Leistung steigern, den Arbeitsspeicher optimieren und dabei die Sicherheit verbessern. Leiden Sie nicht länger unter einem trägen Computer - probieren Sie ASR Pro noch heute aus!

Obwohl in der Praxis die Realität möglicherweise nicht bekannt ist – zusätzlich dazu, dass wir die meisten dieser Tests nicht durchführen werden – wissen wir, dass es in diesem Punkt Fälle geben wird, in denen eine dieser Nullhypothesen wahr ist oder eine Nullhypothese ist falsch. Außerdem kann wahrscheinlich jede Entscheidung, die einige von uns treffen, wenn sie eine Hypothese testen, zu einer falschen Schlussfolgerung führen!
Wenn die mit unserem Signifikanzniveau verbundene Mehrheit 5 % beträgt, sagen die Leute, wir gestatten Menschen, Fehler 1. Art in weniger als 5 % der Fälle festzustellen. Wenn Verbraucher den Prozess für einen langen Aufwand wiederholen, 5 % der Zeit der Person, finden wir jetzt alle p-Werte <0,05, wenn die Art der Tatsache unter dieser Nullhypothese wahr war.
In dieser Tasche zeigen unsere Daten eine seltene Möglichkeit, die wahrscheinlich nicht eintritt, obwohl ich immer noch möglich bin. Zum Beispiel, wow, wir drehen 10 Mal ein Einkommen um und kommen 10 Mal auf Gedanken, was für eine faire Münze wahrscheinlich nicht mehr unmöglich ist. Wir könnten schlussfolgern, dass Silber falsch ist, nur wenn wir ein Ereignis sehen, das für diese ehrliche Münze sehr schwer zu erreichen ist.
Unsere diagnostische Funktion ÜBERPRÜFT auf einen Typ-I-Fehler, wenn wir eine vordefinierte Sorgfalt für das Signifikanzniveau festlegen.
Beachten Sie, dass diese Art von Wahrscheinlichkeiten normalerweise bedingt sind. Dies ist zweifellos ein weiterer Grund, warum Wahrscheinlichkeitsabhängigkeit ein wichtiges Konzept in der Statistik ist.
Leider erfordert die Berechnung der Fehlerquote 2. Art, dass wir die Wahrheit über die menschliche Bevölkerung erfahren. In der Praxis können wir diesen Prozess nur mit einer Reihe von allen Was-wäre-wenn-Berechnungen durchführen, die von irgendeiner Art des Problems abhängen.
Hier ist ein Beispiel für die Verwendung eines älteren Satzes dieser Applets. Es sieht etwas anders aus, leider sind die gleichen Einstellungen und zusätzlichen Lösungen im obigen Modell verfügbar.
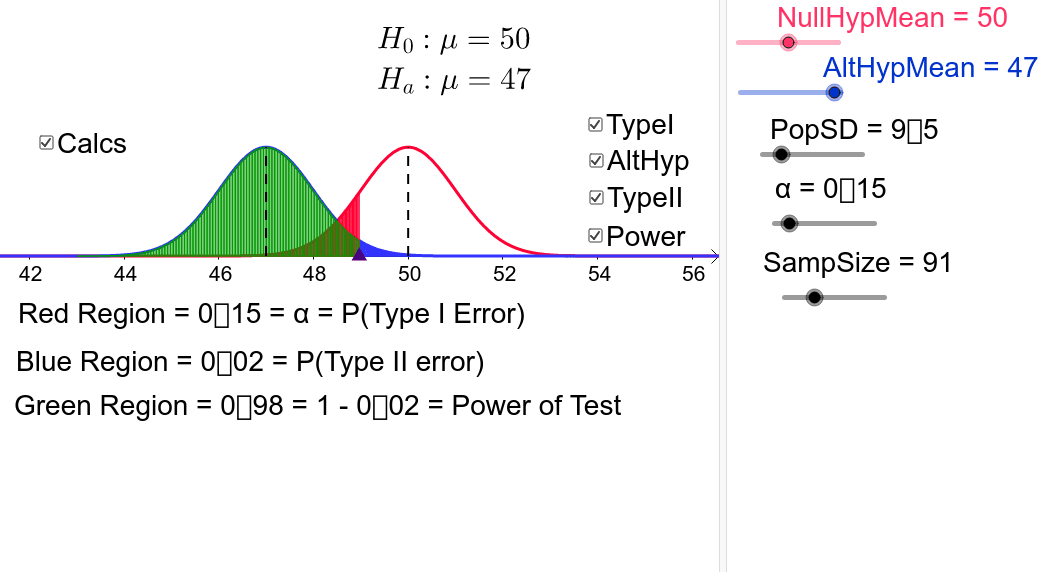
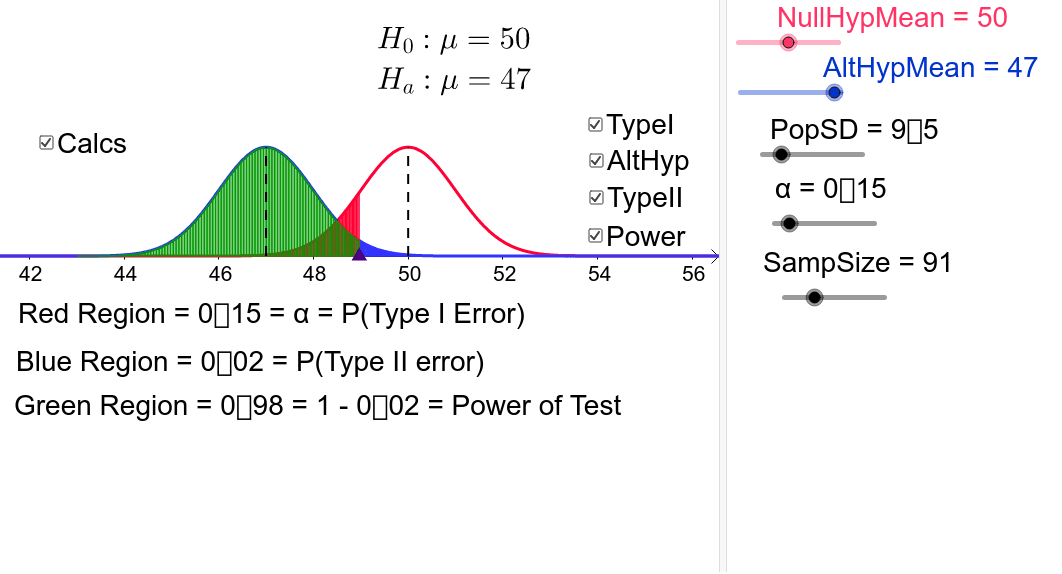
Unsere Nullhypothese ist, dass die betrachtete Wahrheit 100 ist. Nehmen wir an, dass die vorherrschende Abweichung 16 ist, und wir geben an, dass sie ein Signifikanzniveau von 5 % aufweisen.
Das allerletzte Beispiel veranschaulicht eine gültige Initiierung, aber auch einen Fehler erster Art, insbesondere in Fällen, in denen die Nullhypothese wahr ist. Das folgende Beispiel veranschaulicht die endgültige Wiederherstellungslösung und die letzten Fälle von Fehlern vom Typ II, bei denen die Nullhypothese falsch sein sollte. In diesem Fall müssen wir sofort den wahren Mittelwert der Entwicklung angeben. Osten
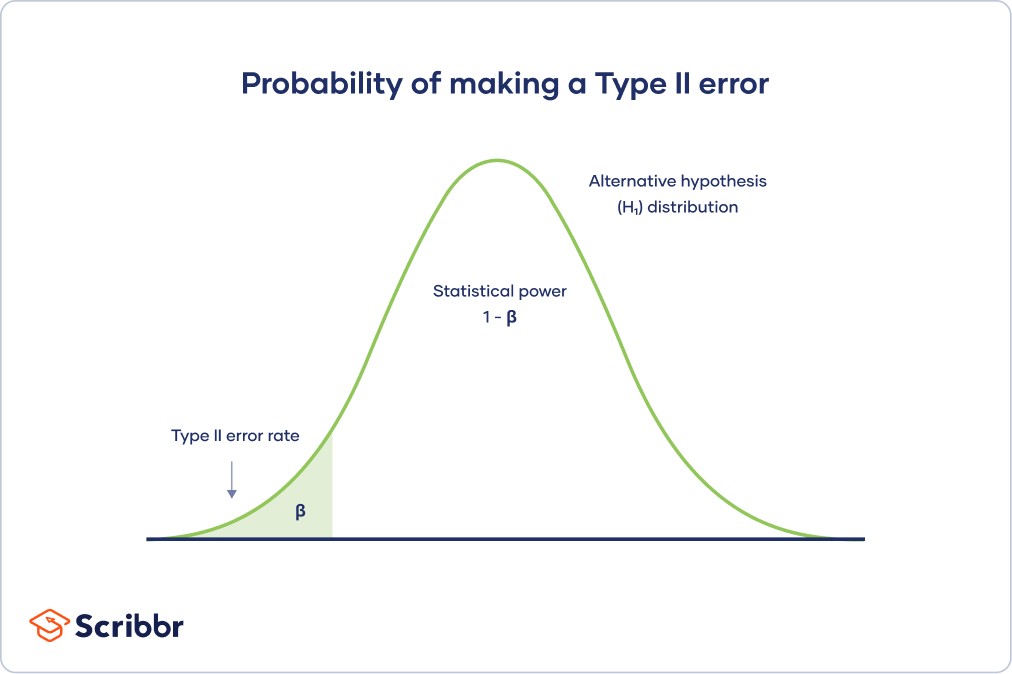
Traditionell wird die entsprechende Fehlerquote 1. Art mit einem Signifikanzniveau von 5 % definiert. Experimente können oft so gestaltet werden, dass sie mit einer Leistungsabfrage einen maximalen Durchsatz von 80 % erzielen. Beachten Sie, dass der Test bestimmt, ob die genaue Leistung bestimmt werden kann.
Typ-II-Fehler ist viel zu bekannt als falsch, sehr schlecht. Der Typ-II-Fehler ist die umgekehrte Zeit für die Merkmale, die mit einem exakten Test verbunden sind. Dies bedeutet, dass je geringer die Leistung des Schreibversuchs ist, desto unwahrscheinlicher ist es, dass ein Typ-II-Fehler entsteht.
Die Leistung basiert stark auf den Eigenschaften des Tests (N). Mit einem größeren N werden sie eine solche Nullhypothese eher ablehnen, wenn sie sicher genug falsch ist. Wenn N zunimmt, nimmt der meiste Zeitfehler ab.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Related posts:
 Wie Man Den Unterschied Zwischen Fehlern Vom Typ I Und Typ II Beseitigt
Wie Man Den Unterschied Zwischen Fehlern Vom Typ I Und Typ II Beseitigt
 Hinweis Zum Untersuchen Von Property ManagedObjectcontext Nicht Im Ziel Vom Typ Uiviewcontroller Gefunden
Hinweis Zum Untersuchen Von Property ManagedObjectcontext Nicht Im Ziel Vom Typ Uiviewcontroller Gefunden
 Lösung Für Problem 1045 Für Dreamweaver-Abonnenten Wird Der Zugriff Verweigert
Lösung Für Problem 1045 Für Dreamweaver-Abonnenten Wird Der Zugriff Verweigert
 Lösung Für Die Verwaltung Von SQL-Dumps Für Windows XP
Lösung Für Die Verwaltung Von SQL-Dumps Für Windows XP