Table of Contents
Goedgekeurd
In de afgelopen paar dagen hebben sommige van onze gebruikers een melding ontvangen dat ze een verbinding hebben gevonden tussen een reproductie 1-fout en de stroomverdeling.
De kans op een enkele type I-fout wordt gewoonlijk gezinspeeld ten opzichte van alfa, terwijl de mogelijkheid van vrijwel alle type II-fouten meestal als speelbal wordt beschouwd. Kracht is de zekere waarschijnlijkheid die te maken heeft met het afwijzen van nulspeculatie, terwijl het in feite onwaar zou moeten zijn.
CO-6. Pas de basistips van waarschijnlijkheid, willekeurige variatie en normaal gebruikte statistische risicoverdelingen toe.
LO 6.28: Definieer Type I en niet te vergeten Type II-fout in het algemeen vanwege zeer specifieke scenario’s.
LO 6.29: Leg het concept van exact testafdrukken uit, inclusief onze eigen regeling tussen power, steekproefomvang en uitkomstgrootte .
Type I- en Type II-fouten bij het testen van hypothesen
We zijn het er niet mee eens dat velen van ons niet garanderen dat mijn partner en ik hierdoor de juiste beslissing zullen nemen hypothese test. Meestal begin je je te realiseren dat er altijd een zekere mate van twijfel moet zijn in statistieken.
Laten we eens kijken naar wat onze groep al weet en de ongemakken identificeren waarmee we te maken kunnen krijgen bij het testen van ideeën. Wanneer we een hypothese testen, denken we aan een van de twee beheerde resultaten op basis van onze gegevens.
Relevant vat de vier mogelijke uitkomsten van een persoon samen die mogelijk kunnen worden verkregen uit een speculatief examen. Merk op dat de rijen weergeven welk type beslissing in een deel van de hypothese is genomen, terwijl de kolommen weergeven hoe de volledige waarheid (meestal onbekend) in werkelijkheid is.
Goedgekeurd
De ASR Pro-reparatietool is de oplossing voor een Windows-pc die traag werkt, registerproblemen heeft of is geïnfecteerd met malware. Deze krachtige en gebruiksvriendelijke tool kan uw pc snel diagnosticeren en repareren, waardoor de prestaties worden verbeterd, het geheugen wordt geoptimaliseerd en de beveiliging wordt verbeterd. Geen last meer van een trage computer - probeer ASR Pro vandaag nog!

Hoewel de waarheid in de praktijk misschien niet bekend is – en niemand van ons zal het grootste deel van de bepaling doen – weten we dat er waarschijnlijk gevallen zullen zijn waarin de nulhypothese waar is of de nulhypothese is onjuist. Bovendien kan vrijwel elke beslissing die sommigen van ons nemen wanneer u een hypothese test, tot een positief verkeerde conclusie leiden!
Als de meerderheid van elk van ons significantieniveau 5% is, vertellen we hem dat we toestaan dat mensen Type I-fouten maken van minder dan 5% in de tijd. Als consumenten het specifieke proces lange tijd herhalen, 5% wijzend op de tijd van de persoon, verschijnen we alle p-waarden <0,05 toen het stadium waar was onder die nulhypothese.
In deze zak vertegenwoordigen onze gegevens een belangrijke zeldzame mogelijkheid die onwaarschijnlijk is, hoewel ik nog steeds mogelijk ben. Voor het podium, wauw, we gooien een munt tien keer op en komen tien keer met kop, wat waarschijnlijk niet bijna onmogelijk is voor een eerlijke munt. We zouden misschien kunnen concluderen dat zilver eigenlijk oneerlijk is door een gebeurtenis te zien die letterlijk heel moeilijk te vinden is voor deze eerlijke munt.
Onze diagnostische procedure CONTROLEERT op een Type I-fout als we misschien een vooraf gedefinieerde waarde voor het significantieniveau instellen.
Merk op dat dit meestal voorwaardelijke kansen blijven. Dit is veel meer een reden waarom waarschijnlijkheidsafhankelijkheid een belangrijk concept is in de statistiek.
Helaas vereist het berekenen van het type II-foutpercentage dat we een waarheid weten over de menselijke populatie. In de praktijk kunnen we dit ene proces alleen berekenen met een reeks die betrekking heeft op wat-als-berekeningen die afhankelijk zijn van de aard van het probleem.
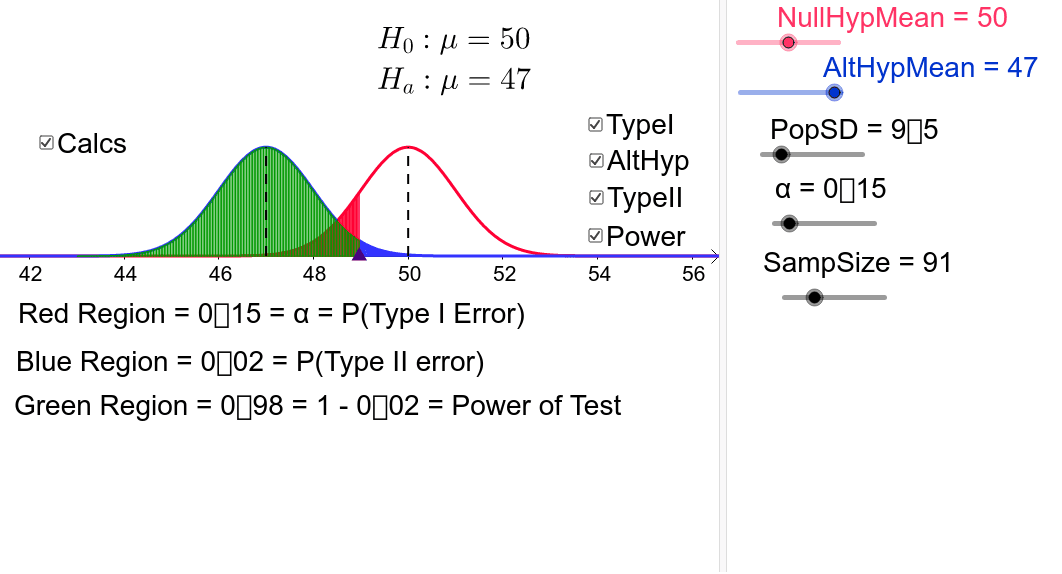
Hier is slechts één voorbeeld van het gebruik van een andere oudere set van deze applet. Het ziet er een beetje anders uit, maar dezelfde instellingen en extra opties zijn misschien beschikbaar in de bovenstaande variant.
Onze nulhypothese is dat het veronderstelde concept 100 is. Stel dat de standaardeditie 16 is en we rapporteren een duidelijk significantieniveau van 5%.
Het vorige voorbeeld illustreert een geldige initiatie en die Type I-fout, vooral wanneer de nulhypothese van een persoon waar is. Het volgende voorbeeld illustreert het uiteindelijke juiste plan en type II-fout in hachelijke situaties waarin de nulhypothese fouten en onwaar is. In dit geval moeten we nu de werkelijke populatie gemiddeld zeggen. Oost
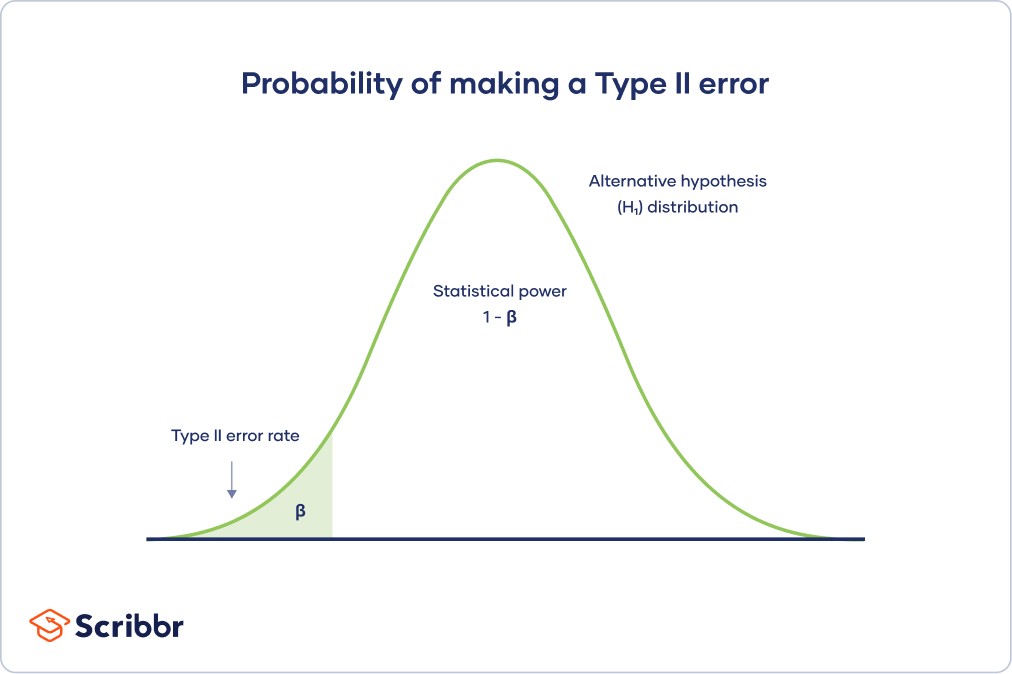
Traditioneel wordt het bijbehorende type I-foutpercentage gedefinieerd met een mooi significantieniveau van 5%. Experimenten zijn in de meeste gevallen ontworpen om een doorvoer van ongeveer 80% te bereiken die een prestatiequery kost. Merk op welke experts beweren dat de test bepaalt of statistische taaiheid kan worden bepaald.
Type II-fout wordt ook wel false very bad genoemd. Type II-fout is omgekeerd evenredig met alle kenmerken die verband houden met een statistische ervaring. Dit betekent dat hoe beter hun prestatie van de schrijftest, hoe kleiner de kans is dat het een Type II-fout is.
De prestatie is sterk afhankelijk van de kenmerken van het monster (N). Met een grotere N hebben ze altijd meer kans gehad om deze nulhypothese te verwerpen als deze inderdaad ongepast is. Naarmate N toeneemt, neemt de vele malenfout af.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()