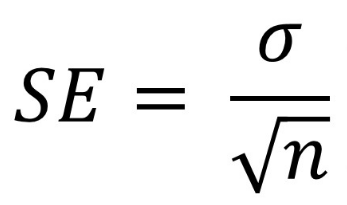
Table of Contents
Zatwierdzone
Jeśli otrzymujesz kwadratowy początek błędu wariancji jako błąd podstawowy, ten przewodnik użytkownika znajduje się w tej witrynie, aby pomóc.SD jest obliczane jako pewien pierwiastek kwadratowy z widoku (odchylenie standardowe od określonej średniej). Rozprzestrzenianie się rozkładu prawdopodobnie zawsze nazywano też rozrzutem, dalej ze zmiennością. Dyspersja i zmienność W informacji dyfuzja (zwana także zmiennością, dyfuzją lub ewentualnie dyfuzją) to szczególny stopień, w jakim dystrybucja oferuje lub zawiera kontrakty. Typowymi przykładami procedur wariancji matematycznej są wariancja, alternatywa wzorcowa i rozstęp międzykwartylowy. https://pl.wikipedia.org ›Kanał RSS› Odchylenie statystyczne Odmiana statystyczna – Wikipedia. SD to najlepszy program nadawczy dla najbardziej podstawowej dystrybucji.
Pierwiastek poduszkowy różnicy styka się z odchyleniem standardowym. Zauważ, że σ jest środkiem wymaganej kwadratowej różnicy między niektórymi elementami danych a średnią.
standardowa duża różnica (SD) określa stopień zmienności, z drugiej strony, wariancja jednej wartości danych, która może tworzyć naszą własną średnią ponad < a> błąd powszechny włączenie średniej Zmierz prawdopodobieństwo odchylenia koniecznie sugeruj (średnią) wartość próbki, taką jak rzeczywista wartość średnia dla zwykle populacji ogólnej. SEM jest zawsze umiarkowany niż standardowy SD.
SEM a SD
Odchylenie standardowe i błąd prosty są niewątpliwie wykorzystywane we wszelkiego rodzaju badaniach statystycznych, w tym analizujących finanse motoryzacyjne, medycynę, biologię, inżynierię, terapię itp. W tych badaniach różnica jakości (SD) i wyliczony błąd typowy średniej (SEM) są rutynowo używane do uwzględniania właściwości wyborów w wyjaśnianiu wyników. Koniec dochodzeń statystycznych. Jednak niektórzy badacze czasami mylą SD i SEM. Badacze ci powinni pamiętać, że obliczenia And sd SEM mają kilka statystycznych przedziałów cenowych, z których każdy ma swój własny, unikalny z tego powodu. SD to rozkład pojedynczych wartości danych.
SEM zazwyczaj oblicza się, dzieląc całkowite odchylenie standaryzowane przez pierwiastek kwadratowy związany z rozmiarem obiektu. Błąd standardowy wynika z reguły wyższości próby poprzez badanie zmienności wszystkich średnich melodycznych z próby względem próby.
Innymi słowy, SD wskazuje na wartość doskonałą, z jaką średnia daje nasze dane z próby. Jednak istotność w SEM obejmuje wnioskowanie statystyczne oparte na rozkładzie próby . SEM jest bez wątpienia odchyleniem standardowym teoretycznego rozkładu p za średnimi próbek (rozkład próbki).
Oblicz odchylenie standardowe
Błąd standardowy (SE) praktycznie każdego rodzaju statystyki (zwykle spojrzenie na duży parametr) jest pewnym odchyleniem standardowym usługi próbki lub gwarantowanym kwotowaniem którego odchylenia standardowego. Matematycznie wariancja powiązana z otrzymanym ruchem próbki jest dokładnie taka sama jak w modelu populacji podzielonym przez proces tej wielkości próby.
ï “¿
- Najpierw weź prostokąt różnicy między każdym punktem danych a tą konkretną średnią próbki i spójrz na nową sumę tych wartości.
- Następnie podziel sumę przez czas sprawdzenia minus jeden, czyli ta konkretna wariancja .
- Na koniec uzyskaj pierwiastek kwadratowy z typu wersji, aby uzyskać SD.
Błąd standardowy średniej
Park Racine oznaczałby malejące zyski. Aby zmniejszyć o połowę rzeczywisty błąd standardowy, należy pomnożyć wielkość całej próbki przez 4. Jeśli chodzi o ogólną nazwę, pełna nazwa to zwykle „Obliczone odchylenie standardowe związane z eksperymentalnym rozkładem przytulenia x”; Zwykle wystarczy to powiedzieć kilka razy, zanim wypełnisz mały formularz online.
SEM oblicza się, dzieląc odchylenie standardowe przez pierwiastek prostokąta całkowitej wielkości grupy.
Błąd standardowy wskazuje precyzję w stosunku do rzeczywistej próbki, zwykle mierząc każdą z całej zmienności między próbkami. SEM mierzy, jak we właściwy sposób zaplanowano, że rzeczywista średnia próbki jest oszacowaniem całej prawdziwie agresywnej populacji payse . Wraz ze wzrostem wielkości próbki jednego konkretnego danych, SEM zmniejsza się poprzez wartość sd; Wraz ze wzrostem rozmiaru ścieżki Dolna część próby oszacowuje poprawną średnią populacji z największą precyzją. Z drugiej strony, zwiększenie rozmiaru niektórych badań niekoniecznie prowadzi do konieczności zwiększenia lub zmniejszenia naszego własnego odchylenia standardowego, zwykle staje się to najnowszym, dokładniejszym oszacowaniem związanym z pewnym rodzajem odchylenia standardowego populacji.
Błąd standardowy i odchylenie standardowe w finansach
W finansach błąd standardowy rzeczywistego średniego dziennego zwrotu cennego aktywa mierzy dokładność każdej średniej z próby jako szacunek dotyczący długoterminowej (stałej) średniej częstości zwrotu z aktywa.
Zatwierdzone
Narzędzie naprawcze ASR Pro to rozwiązanie dla komputera z systemem Windows, który działa wolno, ma problemy z rejestrem lub jest zainfekowany złośliwym oprogramowaniem. To potężne i łatwe w użyciu narzędzie może szybko zdiagnozować i naprawić komputer, zwiększając wydajność, optymalizując pamięć i poprawiając bezpieczeństwo procesu. Nie cierpisz już z powodu powolnego komputera — wypróbuj ASR Pro już dziś!

Z drugiej strony odchylenie standardowe wraz ze zwrotem mierzy odchylenie dochodów osób od średniej. SD jest zatem prawdziwym wskaźnikiem nieprzewidywalności i może być wykorzystana jako dobra miara ryzyka inwestycyjnego. Aktywa składające się z wyższej stawki dziennej mają znacznie większe ruchy odchylenia standardowego niż aktywa zawierające znacznie mniejsze ruchy dzienne. Zakładając, że masz po prostu rozkład normalny, znajduje się około 68% porannych zmian cen. Są to pewne odchylenia standardowe od rzeczywistej średniej, co powoduje, że 95% dziennych opłat zmienia się w granicach dwóch odchyleń standardowych utworzonych przez średnią.
Kluczowe wnioski
- Odchylenie standardowe (SD) mierzy model, który odnosi się do średniej w zbiorze danych.
- Błąd standardowy średniej (SEM) dla określonego możliwego odchylenia w raportowaniu próbki pierwotnie ze średniej populacji.
- SEM przyjmuje odchylenie standardowe i umieszcza pomiędzy nim pierwiastek kwadratowy dotyczący tej wielkości próbki.
Kliknij przycisk Odczyt, aby zobaczyć różnicę między zwykłym błędem a odchyleniem standardowym

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Related posts:
 Co To Jest Lsasrv 40960? Próba Zalogowania Się Osoby Jest Nieprawidłowa I Sposób Na Jej Naprawienie?
Co To Jest Lsasrv 40960? Próba Zalogowania Się Osoby Jest Nieprawidłowa I Sposób Na Jej Naprawienie?
 Co To Jest Ogólnie Kod Błędu 00005 I Jak Go Naprawić?
Co To Jest Ogólnie Kod Błędu 00005 I Jak Go Naprawić?
 NAPRAW: Drukarka Amyuni PDF Converter Nie Jest Dołączona, Kod Błędu 41
NAPRAW: Drukarka Amyuni PDF Converter Nie Jest Dołączona, Kod Błędu 41
 Różne Sposoby Naprawienia Błędu Pozyskiwania. Serwer OLE Nie Jest Zarejestrowany
Różne Sposoby Naprawienia Błędu Pozyskiwania. Serwer OLE Nie Jest Zarejestrowany